Twitter being down is no longer funny, nor is it even news anymore and the same is the case with Twitter-angst, where loyal users fret and fume about how often it is down. One of the interesting suggestions that have come out as a result of this is to
create a
decentralized version of Twitter – much on the lines of IRC – to bring about much better uptimes for the beleaguered child of
Obvious Inc.
I would take the idea a lot further and argue that all social communication products should gradually turn into aggregation points. What I am proposing is a new social data framework, let us call it HyperID (since it would borrow and use heavily ideas and concepts from
OpenID), from which social media websites would subscribe, push and pull data from.
Essentially, this would involve the publication of the user’s social graph as the universal starting point for services and websites to subscribe to, rather than the current approach where everyone is struggling to aggregate disparate social graphs as the end point of all activities. Ergo, we are addressing the wrong problem at the wrong place.
The current crop of problems will only be addressed when we stop pulling data into aggregators and start pushing data into service and messaging buses. Additionally, since this data is replicated across all subscriber nodes, it should also provide us with much better redundancy.
Problem Domain
Identity: Joe User on Twitter may not always be the same as Joe User on Facebook. This is a known problem that makes discovery of content, context and connections tricky and often downright inaccurate. Google’s
Social Graph API is a brave attempt at addressing this issue using
XFN and
FOAF, but it won’t find much success because it is initiated at the wrong end and also because it is an educated guess at the best and you don’t make those with your personal data or connections.
Disparate services: Joe User may only want to blog and not use photo sharing on the same platform, unlike Jane User who uses an entire gamut of services. In an even worse scenario, if Jane User wants to use blogs on a particular service provider (say, Windows Live Spaces) and photo sharing on another (Flickr, for instance), she will have to build and nurture different trust systems, contacts and reputation levels.
Data retention: Yes, service providers are now warming up to the possibility of allowing users to pull out user data from them, but it is often provided without metadata or data that is accrued over time (comments, tags, categories etc). Switching providers often leaves you with having to do the same work all over again.
Security: Social information aggregators now collect and save information by asking you for passwords and usernames on other services. This is not a sane way to work (extremely high risk of phishing) and is downright illegal at times when it involves HTML scraping and unauthorized access.
Proposed solution
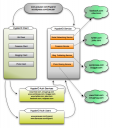
Identity, identity, identity: Start using OpenID as the base of HyperID. Users will be uniquely addressable by means of URLs. Joe User can always be associated with his URL (
http://www.joeuser.com/id/), independent of the services he has subscribed to. Connections made by Joe User will also resolve to other OpenIDs. In one swipe you no longer have to scrape or crawl or guess to figure out your connections.
Formalize a social (meta)data vocabulary: Existing syndication formats like
RSS and
ATOM, are usually used to publish text content. There are extensions of these formats like
Media RSS from Yahoo!, but none of them address the social data domain.
Of the existing candidates, the Atom Publishing Protocol seems to be the most amenable to an extension like this to cover the most common of social data requirements. Additional and site-specific extensions can be added on by means of custom namespaces that define them.
You host your own social graph: With a common vocabulary, pushing, pulling and subscribing to data across different providers and subscribers should become effortless. This would also mean that you can, if you want to, host your own social graph (
http://www.janeuser.com/social) or leave it up to service providers who will do it for you. I know that
SixApart already does this in part with the
Action Streams plugin, but it is still a pull than a push service.
Moreover, we could extend the autodiscovery protocol for RSS and use it to point to the location of the social graph, which is a considerably better and easier solution than the one proposed Social Graph.
Extend and embrace existing tech: Extend and leverage existing technologies like OpenID and Atom to authenticate and advertise available services to users depending on their access levels.
What this could mean
For companies: They have to change the way they look at usage, data and their own business models. Throwing away locked-in logins would be a scary thing to do, but you get better quality and better-profiled usage.
In the short run you are looking at existing companies changing themselves into data buses. In the longer run, it should be business as normal.
Redundancy: Since your data is replicated across different subscribers, you can push updates across to different services and assign fallbacks (primary subscriber: twitter, secondary: pownce and so on).
Subscriber applications can cache advertised fallback options and try known options if the primary ones are unavailable.
For users: They will need to sign up with a HyperID provider or host one on their own if they are savvy enough to do that. On the surface, though, it should all be business as usual, since a well-executed API and vocabulary should do the heavy lifting behind the scenes.
The Opportunity
For someone like WordPress.com, diversifying into the HyperID space would be a natural extension. They could even call it Socialpress. The hypothetical service would have a dashboard like interface to control your settings, subscriptions and trusted users and an API endpoint specific to each user.
Risks
Complexity: Since data is replicated and pushed out across to different subscribers, controls will be granular by default and across different providers this could prove to be very cumbersome.
Security: Even though attacks against OpenId has not been a matter of concern, extending it would bring with it the risk of opening up new fronts in what is essentially a simple identity verification mechanism.
Synchronization: Since there is data replication involved (bi-directional like any decent framework should do), there is the possibility that lag should be there. Improperly implemented HyperID compliant websites could in theory retain data should be deleted across all subscribed nodes.
Traction: Without widespread support from the major players the initiative just won’t go anywhere. This is even more troublesome because it involves bi-directional syncing and all the parties involved are expected to play nice. If they don’t, it just won’t work. We could probably get into certification, compliance and all that jazz, but that would make it insanely complicated.
Exceptions: We are assuming here that users would want to aggregate all of their things under a single identity. I am well aware of the fact that there are valid use cases where users may want to not do that. HyperID does not prevent from doing. In fact, you could use different hyperIDs, or even specify which services you don’t want to be published at all.
Feedback
The comment space awaits you!
p.s: Apologies for the crappy graphic to go with the post. I am an absolute newbie on Omnigraffle and it shows!

